
Какой python медленный и почему?
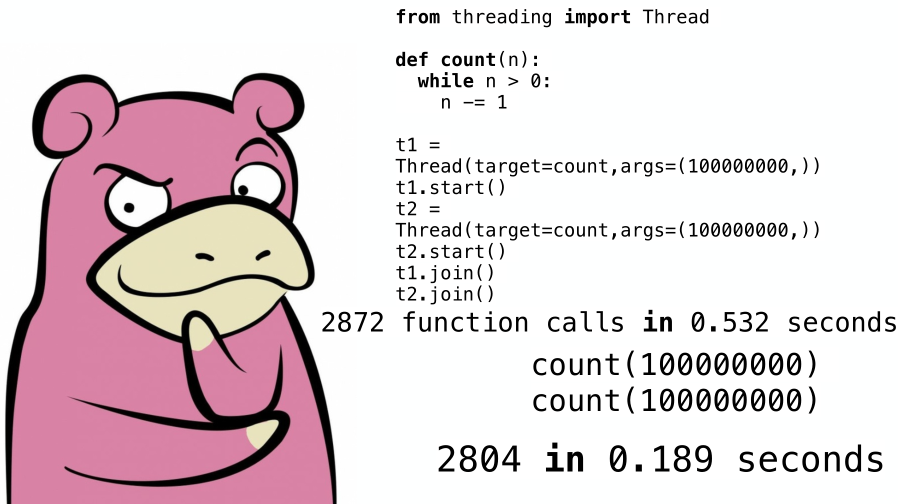
Пару лет назад у меня было несколько свободных часов, которые я посвятил сравнению наиболее распространенных реализаций python между собой, а также почему при написании многопоточного кода время выполнения может только замедлиться (на изображении выше как раз показан один из простых примеров).
Один из заданных после доклада вопросов меня тогда смутил, а расширение тематики у блога позволило не только опубликовать материал тут, но и дополнительно разобраться в том вопросе. Подробности под катом.
Питон действительно простой и уже достаточно популярный язык. Вокруг него сформировалось огромное сообщество, которое написало кучу библиотек под самые разные нужды, позволяющие сегодня делать сложные проекты буквально на коленке, в хорошем смысле. Однако, простота и гибкость языка компенсируется проблемами в производительности. В масштабах «очередного сайта на django» проблема не будет заметно, но многие компании, использующие или которые использовали питон в своих сервисах, столкнулись с проблемами при росте нагрузки.
На сегодняшний день питон — один из самых медленных среди скриптовых языков. Из более медленных языков остается lua и tcl, например.
Какие у питона проблемы? Многие вспоминают классические причины низкой производительности у скриптовых языков: динамическая типизация, сборщик мусора, отсутствие нативных типов для примитивов (числа, байт-массивы и прочее). Вот только эти «проблемы» есть у, например, php и js, однако, работают они быстрее. На самом деле упомянутые ранее причины на допустимом уровне, если так можно выразиться, замедляют время выполнения. Как раз та самая плата за быстроту разработки. Но при этом исполнение питоновского кода сопровождается большой лишней работой.

На изображении выше показано несколько слайдов с количеством системных вызовов для кода, который будет приведен далее. Первый столбец — python3, второй — php7. Итоговые результаты ниже (суммарное количество системных вызовов и примерное время выполнения в секундах).
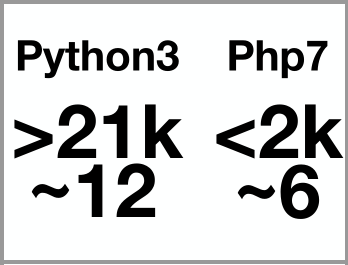
Как итог, получается, что сама по себе интерпретация безусловно работает медленнее, чем, например, нативный код, но интерпретатор интерпретатору рознь, и одну и туже работу можно делать лучше или хуже.
А что насчет многопоточной работы?
На эту тему есть очень хороший доклад, который не смотря на дату своей публикации не потерял актуальности. Если в вкратце: в питоне для работы с потоками существует GIL. Этот модуль на каждый поток отводит определенное количество времени выполнения, после чего переключается на следующий. В python2 не было привязки к реальному времени, двум разным по временным затратам инструкциям отводилось одинаковое количество «тиков», что приводило к просадкам и появлению мемов про GIL.
Однако, на сегодняшний день это проблема исправлена и более того, в случае, когда выполнение уходит в нативный код, GIL перестает действовать, что положительно сказывается на суммарных временных затратах.
Нужна ли эта оптимизация вообще?
Вообще в чем бы то ни было должна быть необходимость, в том числе и в оптимизации. И если на текущий момент медленная работа (в сравнении с возможными реализациями на других технологий) не вызывает проблем (в данном случае проблемы не абстрактны а могут быть измерены в денежном эквиваленте) и вероятнее всего не вызовет в будущем, то такие оптимизации буду преждевременными. А значит время специалистов будет потрачено зря.
Для понимания того, что проблем с производительностью действительно нет, а не просто так кажется, хорошо помогают нагрузочные тесты.
Если при прохождении нагрузочных тестов остается еще около 30% ресурсов в резерве, при этом код на продакшене справляется со своим функционалом и не прогнозируется увеличение нагрузки (например, такими могут быть сезонные периоды праздников для магазинов), то трогать его не имеет смысла.
То есть, в первую очередь оптимизировать нужно только если в этом есть необходимость.
При достаточно объемном участке кода, подлежащим оптимизации (при работе с библиотекой, например, или микросервисом) необходимо выявить наиболее медленный участок. Здесь работает известный закон Парето: 20% усилий дают 80% результата.
На практике как это обычно бывает: поступает тикет с проблемой в фиче Х. Имплементация этой фичи уже сам по себе какой-то определенный отрезок в проекте, который профилируют и из него выделяется наиболее медленный. Пресловутая фраза: "Надо смотреть”, она относится как раз к выявлению этого участка. И сама оптимизация происходит именно с ним.
При этом вполне может выясниться, что наиболее медленный участок приложения — запрос в СУБД, а вовсе не код на питоне.
Как узнать что именно работает долго?
Для этого существуют профилировщики кода. Профилировщиков для питона существует несколько, два из них встроены в платформу: cProfile и profile. Оформлены они в виде модулей. Для запуска профилировщика достаточно указать названия модуля в аргументах (-m cProfile/profile). Отличий в выводе никаких нет, все отличия только в том что cProfile накладывает меньше оверхеда на работу, т.к. написан на С. Просмотр и анализ данных профилирования происходит с помощью поставляемого вместе с питоном модуля pstats.
Для более наглядного отображения есть несколько утилит, которые графически интерпретируют результат. Среди десктопных это, например, kcachegrind, runsnakerun.
Есть утилита gprof2dot, которая генерирует png с деревом вызовов и информацией о времени выполнения. И, конечно, для любимого django есть django-extensions с командой runprofileserver. Также есть пакет django-silk - профилировщик кода выполняемых sql-запросов. Для вывода дерева вызовов используется gprof2dot.
Для flask есть flask-profiler, который также работает через веб-интерфейс и может показывать бутылочное горлышко приложения, наиболее медленный/часто используемый эндпоинт, какие данные его нагружают и прочее.
Какая реализация наиболее быстрая?
Были взяты следующие реализации: CPython, Pypy, Nuitka , Cython. Первая в качестве стандарта, вторая — реализация JIT-компиляции, две последних — компиляция в исполняемый файл. Код, который использовался при расчетах, опубликован ниже.
import math
import sys
import time
import cProfile
def profile(func):
"""Decorator for run function profile"""
def wrapper(*args, **kwargs):
#profile_filename = func.__name__ + '.prof'
profile_filename = '_'.join(sys.argv) + '.prof'
profiler = cProfile.Profile()
result = profiler.runcall(func, *args, **kwargs)
profiler.dump_stats(profile_filename)
return result
return wrapper
def is_prime(num):
"""Checks if num is prime number"""
for i in range(2, int(math.sqrt(num)) + 1):
if num % i == 0:
return False
return True
def get_prime_numbers(count):
"""Get 'count' prime numbers"""
prime_numbers = [2]
next_number = 3
while len(prime_numbers) < count:
if is_prime(next_number):
prime_numbers.append(next_number)
next_number += 1
return prime_numbers
@profile
def main():
try:
count = int(sys.argv[1])
except (TypeError, ValueError, IndexError):
sys.exit("Usage: test.py number)
if count < 1:
sys.exit("Error: number must be greater than zero)
prime_numbers = get_prime_numbers(count)
print("Answer: %d" % prime_numbers[-1])
if __name__ == '__main__':
millisBefore = time.time()
main()
millisAfter = time.time()
print("Exec time: " + str(millisAfter - millisBefore))
А вот и таблица с результатами:
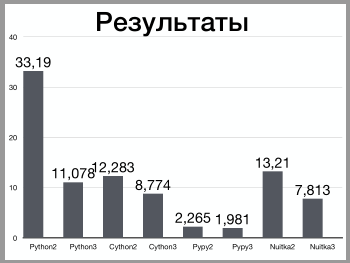
Также следует обратить внимание на строку for i in range(2, int(math.sqrt(num)) + 1):. Возвращаясь к теме вопроса, который смутил, мне правильно указали, что у python2 есть функция xrange, которая работает быстрее. Однако, функции нет в в третьей версии, а значит код уже будет зависим от версии. Также можно использовать пакет six. В таблице ниже приведены всевозможные сочетания с учетом этого дополнения.
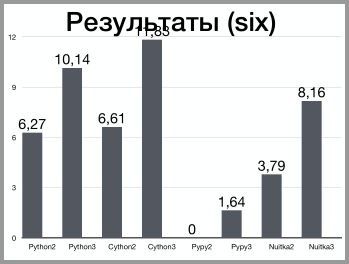
Интересная вещь произошла с pypy2: он отказался запускаться, аргументировав это тем, что нет модуля six.
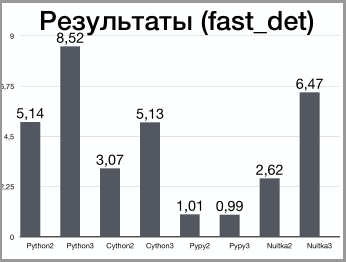
Можно пойти дальше и переписать функцию проверки на то что число простое по-другому:
def is_prime(n):
if n <= 3:
return n > 1
elif n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i*i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i+= 6
return True
И также таблица с рассчетами
Вместо заключения
Какие бы тесты не делал, выходит что если есть возможность использовать pypy3, то нужно эту возможность использовать.
Целью не стояло назвать питон плохим потому что он работает медленнее относительно чего-то другого. Если инструмент справляется со своей задачей, и результат не вызывает проблем, а особенно важно - не вызовет проблем в ближайшем будущем, значит инструмент подобран грамотно. Скорее двигало банальное желание разобраться в том, что происходит внутри в теории и как это отражается на практике, а затем сравнить эту самую практику в некоторых реализациях языка, после чего рассказать об этом тут.